 OCRmyPDF adds an invisible text layer to PDF documents after passing it through the Tesseract OCR engine. The output will be PDF/A with a selectable but invisible text layer above scanned image-documents. This allows later searching and archiving.
OCRmyPDF adds an invisible text layer to PDF documents after passing it through the Tesseract OCR engine. The output will be PDF/A with a selectable but invisible text layer above scanned image-documents. This allows later searching and archiving.
 OCR powered screen-capture tool to capture information instead of images * Many languages * Works offline * Heuristic parsing * Multi monitor * Cross-platform * Free & Open Source
OCR powered screen-capture tool to capture information instead of images * Many languages * Works offline * Heuristic parsing * Multi monitor * Cross-platform * Free & Open Source
 tesseract-ocr is an OCR engine originally developed by Hewlett Packard and now sponsored by Google. It is highly accurate and will read a binary, gray, or color image and output text.
tesseract-ocr is an OCR engine originally developed by Hewlett Packard and now sponsored by Google. It is highly accurate and will read a binary, gray, or color image and output text.
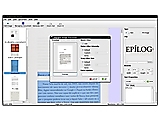 OCRFeeder is a document layout analysis and optical character recognition system. Given the images it will automatically outline its contents, distinguish between what's graphics and text and perform OCR over the latter. It generates multiple formats being its main one ODT. It features a complete GTK graphical user interface that allows the users to correct any unrecognized characters, defined or correct bounding boxes, set paragraph styles, clean the input images, import PDFs, save and load t
The ever growing collection of tools to assist with OCR (optical character recognition).
Free Open Source Document Management System
go-ocr is a tool for extracting plain text from scanned documents in pdf or djvu formats, and postprocessing of the text using user-defined rewriting rules to remove OCR artefacts and irregularities.
OCRPDF is a tool for extracting plain text from scanned documents and postprocessing of the text using user-defined rewriting rules to remove OCR artefacts and irregularities.
OCRFeeder is a document layout analysis and optical character recognition system. Given the images it will automatically outline its contents, distinguish between what's graphics and text and perform OCR over the latter. It generates multiple formats being its main one ODT. It features a complete GTK graphical user interface that allows the users to correct any unrecognized characters, defined or correct bounding boxes, set paragraph styles, clean the input images, import PDFs, save and load t
The ever growing collection of tools to assist with OCR (optical character recognition).
Free Open Source Document Management System
go-ocr is a tool for extracting plain text from scanned documents in pdf or djvu formats, and postprocessing of the text using user-defined rewriting rules to remove OCR artefacts and irregularities.
OCRPDF is a tool for extracting plain text from scanned documents and postprocessing of the text using user-defined rewriting rules to remove OCR artefacts and irregularities.
|